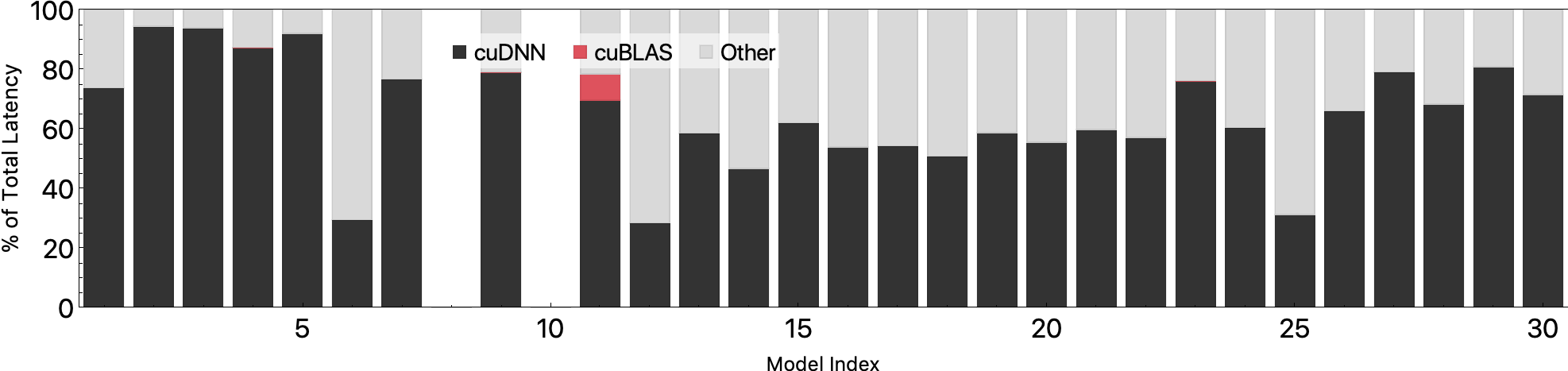
Performance Breakdown
We evaluate the performance of MXNet on a Tesla_V100-SXM2-16GB and classify the end-to-end performance based on whether they fall into CUDNN, CUBLAS, or other calls. As shown bellow, both CUBLAS and CUDNN dominate the end-to-end inference latency.
Batch Size 1
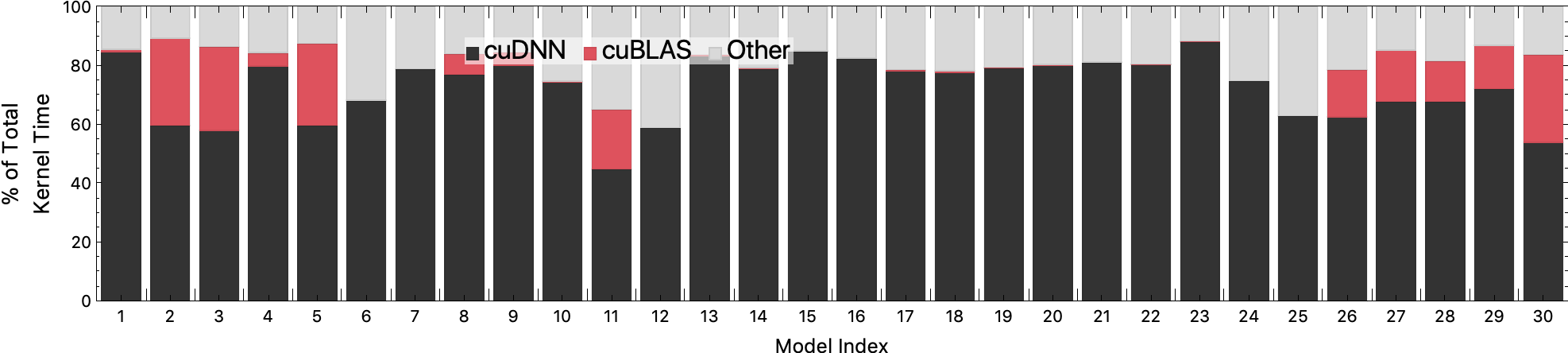
Batch Size 2
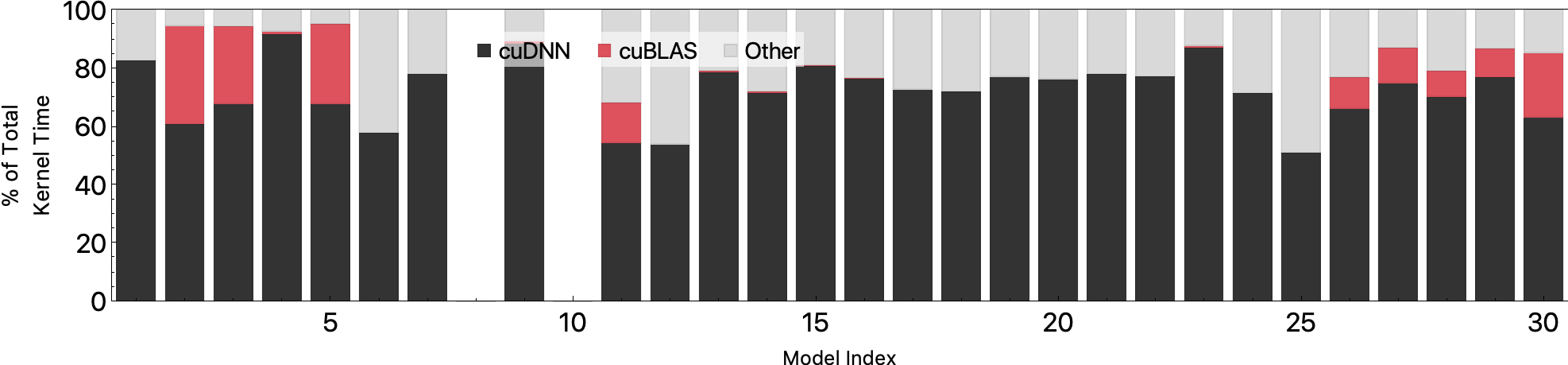
Batch Size 4

Batch Size 8
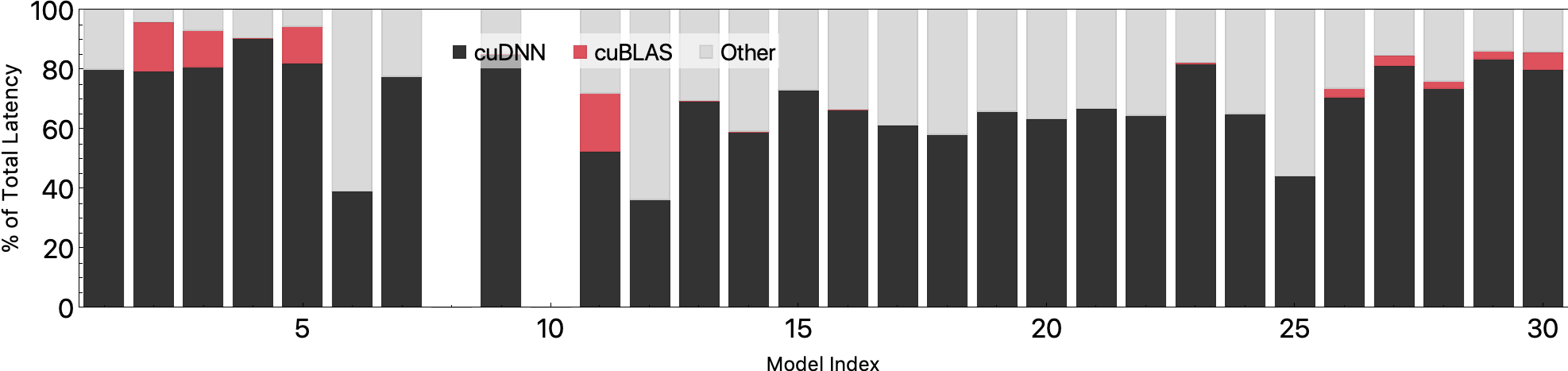
Batch Size 16
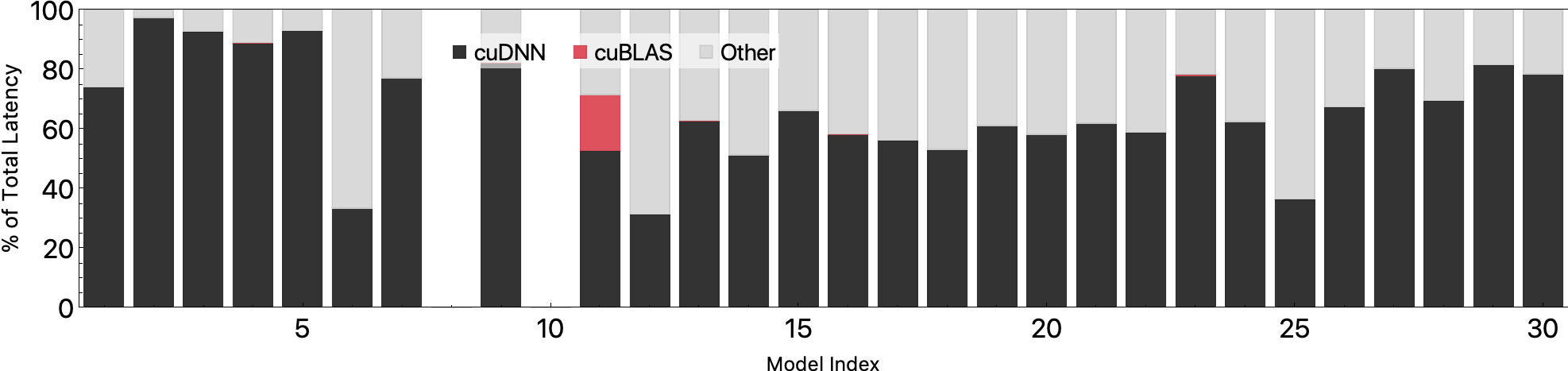
Batch Size 32